| x86 Stuff
|
| I just like fractals and tiny intros ;-)
|
Demoscene releases (any date)
As I'm a bit too lazy to maintain the same content twice you should check out my demoscene related releases from the last few years directly on the Pouet webseite Here's the link.
|
|
|
Kaliskop (07/11/2016)
A 256 byte fractal intro with some midi sound based on Kali's fractal formulas. Released at Demosplash demo party, placed #4 in the combined demo compo. Here's a YouTube link.
| Download
|

|
You are invaded (10/09/2016)
A 256 byte funtro with some interesting ending ;-) Released at Function demo party, placed #5 in the 256 byte compo. Here's a YouTube link.
| Download
|

|
Crystal Comet (10/05/2016)
My first 128 Byte intro for DOS including sound. The theme is "...as I chased the shaking crystal comet through space I began to hear those mysterious sounds...". Released at Outline demo party, placed #7 in the 128 byte compo. Here's a YouTube link, but you should watch it with DOSBox as the encoder quality of Youtube isn't really good.
| Download
|

|
aldeshul (12/09/2015)
My second 256 Byte intro for DOS. Some feedback zoomer with text and Lissajou...also find a sound enhanced version without the Lissajou in the extra folder. Released at Function demo party, placed #11 in the 256 byte compo. Here's a YouTube link.
| Download
|

|
fishy (16/05/2015)
My first 256 Byte intro for DOS. An experiment to do something usefull with bezier lines...there's an extra folder with a procedural graphics based on the same technique. Released at Outline demo party, placed #6 in the wild compo. Here's a YouTube link.
| Download
|

|
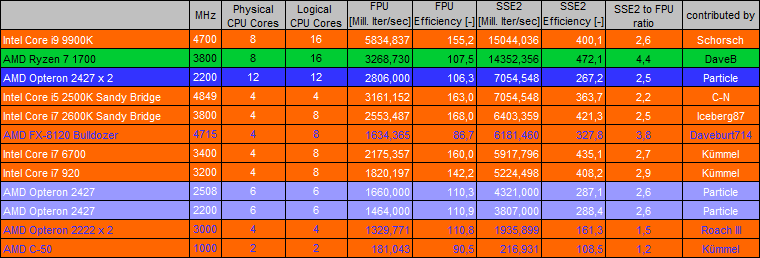
KMB V 0.53I-32b-MT Results (listed in order of SSE2 or SSE4.1 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Physical CPU cores) |
 |
|
Kümmel Mandelbrot Benchmark V 0.53I-32b-MT (11/01/2009)
Logical CPU core detection implemented. This sets also the maximum of threads created (before always set to 16 threads, what can cause some overhead). Furthermore the display of logical CPU cores and CPU brand was implemented for the result message box. Also the Windows code that caused problems on some machines was corrected. Iteration code remains unchanged for SSE2 and FPU.
| Download
|

|
Kümmel Mandelbrot Benchmark V 0.53H-32b-MT (01/06/2008)
Another improvement of the FPU version and the SSE2 version. The FPU version has now 3 iterated points loop with 3 independent instruction lines and 3 times loop unrolling. The SSE2-Version was also extended to 3 times loop unrolling, which was beneficial for Core2Duo and AMD's but not for Pentium M's. So to support them a special version (which is in fact V0.53H_SSE2) is included. Speed up for the FPU version is up to 40 % and SSE2 of up to 14 % depending on the type of CPU compared to Version 0.53H.
| Download
|
|
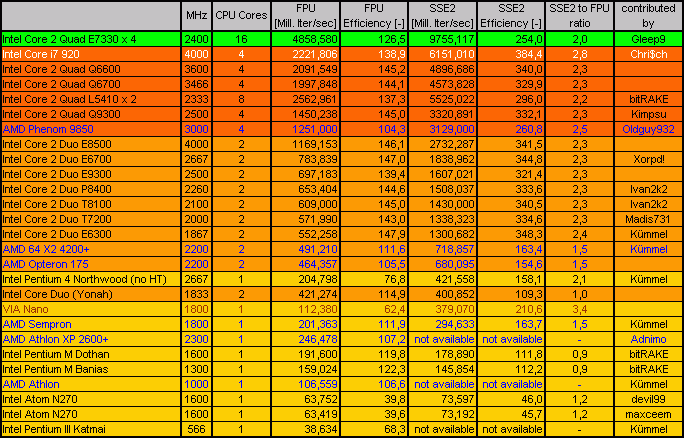
KMB V 0.53H-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
Kümmel Mandelbrot Benchmark V 0.53G-32b-MT (13/04/2008)
After leaving the FPU version all the time behind I took the effort to implement all lessons learned from the SSE2 optimization and created a much faster FPU version with 2 points iteration loop and loop unrolling one time. About 40 to 90 % faster than the original version. The SSE2-Version remains unchanged.
| Download
|
|
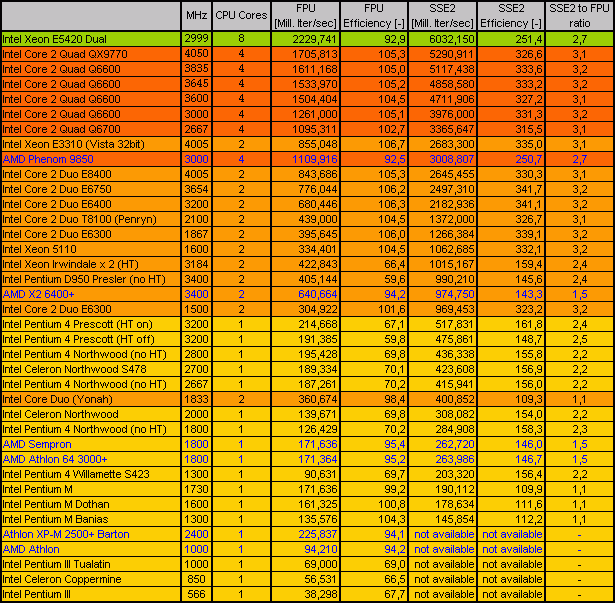
KMB V 0.53G-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
Kümmel Mandelbrot Benchmark V 0.53F-32b-MT (02/04/2008)
The SSE2 version now finally uses 6 exits of the inner loop and so no iterations are wasted to wait for other points to diverge or reach maximum iterations. Iteration counter is now done with integers to reduce the necessary memory access if SSE2 counters would have been used. Overall about 20 % faster than the last version. I also doubled the duration of the benchmark to have more stable results. The FPU-Version remains unchanged, I hope to enhance it also one day as there are some possibilities, too.
| Download
|
|
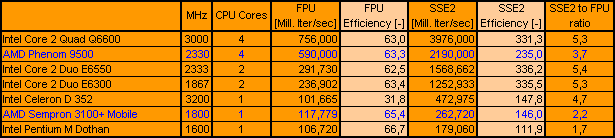
KMB V 0.53F-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
Kümmel Mandelbrot Benchmark V 0.53E-32b-MT (17/01/2008)
These Version seems to be best for INTEL and AMD, except Pentium M. One can't do it right for everyone, but for now I favour this version in respect to Phenom and Core 2 Duo.
|
Download
|
|
KMB V 0.53E-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
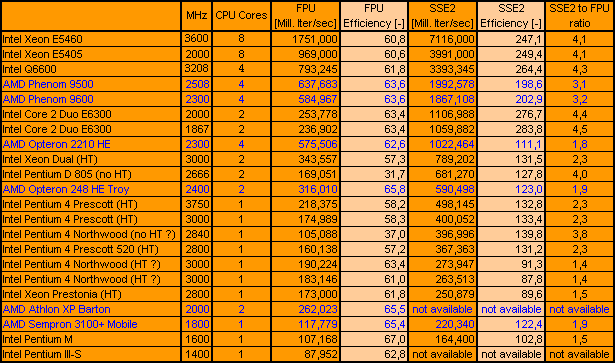 |
|
Kümmel Mandelbrot Benchmark V 0.53D-32b-MT (13/01/2008)
Another major improvement, now at about the double speed of the original version. Thanks to Xorpd! I also include now an AMD optimized version, to be more fair to each company's cpu features. There's still air for some more optimizations but the limit is more close now, I guess.
|
Download
|
|
KMB V 0.53D-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
Kümmel Mandelbrot Benchmark V 0.53C-32b-MT (04/01/2008)
Much improved version of my old V 0.53 MT. The improvments are only for the SSE2 version, FPU stays the same. The code is mainly influenced by Xorpd!s 64bit OS versions (see below) and speeds up calculations on an Intel Core 2 Duo 70 % compared to the old version. Yet there's still plenty of options for further speedup.
|
Download
|
|
FASM - 'INCLUDE' for Kümmel Mandelbrot Benchmark V 0.53C-32b-MT (04/01/2008)
If you got problems compiling the source code of KMB, this INCLUDE directory for FASM might help. Note: This one is different to the INCLUDE from the old KMB V0.53 Version. One day I'll try to make it run with the standard delivered FASM Include
|
Download
|
|
KMB V 0.53C-32b-MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
Xorpd! did a x64 OS version of my KMB V 0.53 MT version that gains amazing speedups ! See the results of the KMB V 0.57 MT here:
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |

|
|
Kümmel Mandelbrot Benchmark V 0.53 MT (11/07/2006)
A Benchmark desired to detect the double precision floating point power of x86 CPU's by calculating a bunch of fractals either with the standard FPU or the SSE2 unit. Version 0.52 now supports Multi-Threading up to 16 Threads instead of the 2 Threads of the previous version giving huge benefit on multi CPU systems. Some results are published below. More info in the 'Read Me'. Post some more results to me if you like ! Written in x86 assembler/FASM format.
|
Download (18 KByte)
|
|
FASM - 'INCLUDE' for Kümmel Mandelbrot Benchmark
If you got problems compiling the source code of KMB, this INCLUDE directory for FASM might help.
|
Download (97 KByte)
|
|
KMB V 0.53 MT Results (listed in order of SSE2 performance):
(Efficiency is calculated like = 1000 Iterations / MHz / Core) |
 |
|
FRAC! V 1.0 (02/06/1997)
A full menu driven fractal application for DOS, including different algorithms, 3D-display, coulour-rotation, load and save of the data. Still working on XP but incredibly slow...written in C with and compiled with ancient Turbo-C.
|
Download (56 KByte)
|

|
